AI’s Last-Mile Problem — Why Great Models Underperform in Operations
85% of AI projects fail. LexData Labs’ four-part framework helps close AI’s “last-mile” gap, moving models from pilots to production with real ROI.

Executive Summary
· Failure rates remain high: Roughly 85% of AI projects never deliver value. One global survey found only ~11% of firms achieve significant financial returns from AI at scale.
· Pilot purgatory persists: An estimated 70–90% of machine learning models never make it out of the lab. Most AI initiatives stall at proof-of-concept, with minimal business impact.
· Cost of idle AI: The average AI pilot takes over a year and costs upwards of $1 million—yet many models end up shelved, wasting billions in sunk investment.
· Closing the “last mile” gap: We propose a four-part framework – Deployability by Design, Model–Workflow Co-Design, MLOps Discipline, and an Ownership & Trust Layer – to operationalize AI and bridge the gap from prototype to production.
· Value of success: Organizations that master the last mile see faster time-to-value, lower operational risk, and a sustained edge over rivals stuck in perpetual pilots.
What is the “last mile” in AI?
Borrowing from logistics, the “last mile” is the shortest physical distance yet the hardest, most expensive part of parcel delivery. In AI, the last mile is the final stretch from a validated model to a value-creating production system. It begins the moment a data science team declares “model ready” and ends only when: (1) the model is running in production on live data; (2) its outputs are embedded in business workflows; and (3) performance is being monitored, governed, and continuously improved.
Everything that can go wrong in that stretch – brittle data pipelines, integration friction, user distrust, compliance hurdles – constitutes a last-mile challenge. In short, it’s the chasm between a promising prototype and a practical, trusted tool in daily operations.
Why last-mile failure is pervasive
Pilot-to-production drop-off. Numerous studies show a persistent “AI pilot purgatory.” IDC research found 88% of AI proof-of-concepts never reach wide-scale deployment. In other words, only a small fraction of lab models ever make it to full production in the real world.
“Zombie models.” Even when deployed, many models end up underutilized or ignored. Dashboards go unread, automated alerts are tuned out, and front-line decisions quietly revert to gut instinct. Models without real adoption might as well be dead.
Return-on-AI paradox. Despite heavy investment, tangible returns remain elusive. One MIT-BCG analysis noted that only about 1 in 10 companies truly reap significant financial benefits from AI at scale. There’s a stark disconnect between AI activity and AI impact. As of 2025, a McKinsey/WSJ survey found only 1% of U.S. firms that invested in AI have successfully scaled those projects across the enterprise, while 43% remain stuck in pilot stage.
The net effect is wasted investment – one recent study estimates over 80% of AI projects fail, representing billions in sunk costs – along with heightened operational risk and strategic frustration. Leadership teams see AI promise in demos, but not in the P&L, eroding confidence in further AI spend.
Industry data underscore these gaps. In fact, the proportion of AI projects that successfully move from pilot to production – and the share of deployed projects delivering meaningful ROI – has declined in recent years. This suggests that as organizations take on more ambitious AI initiatives (e.g. complex generative models), the last-mile challenge is growing even tougher.
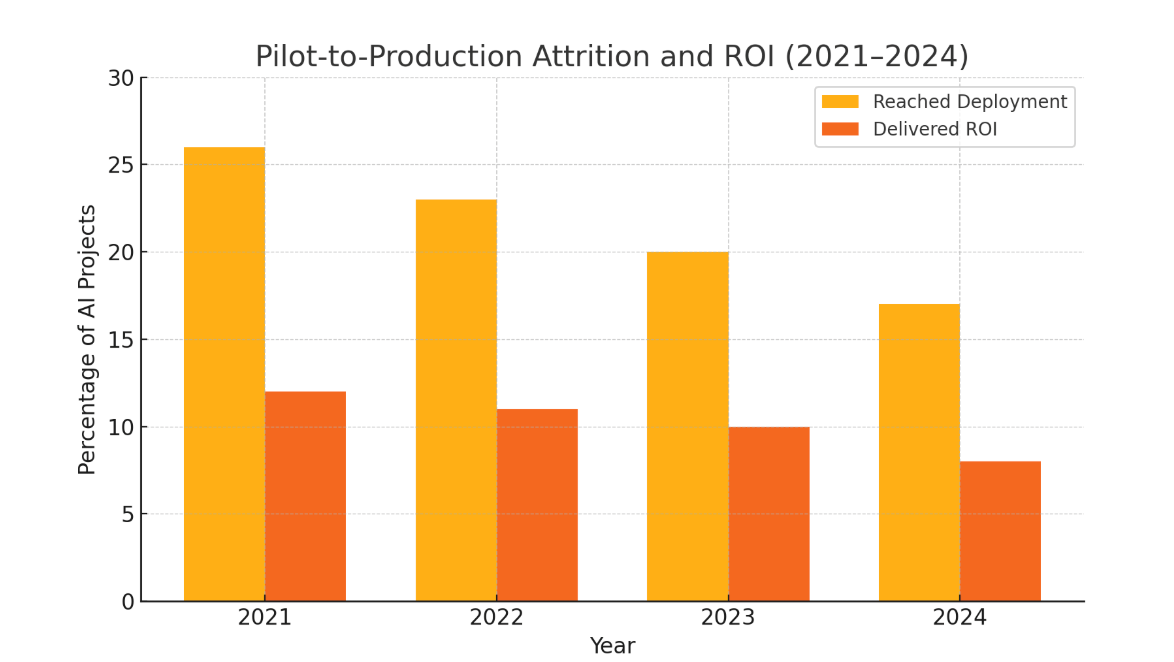
Beyond lost opportunity, last-mile failures carry a direct financial toll. The average AI project can take over a year and require a seven-figure budget to complete – an investment that may never be recouped if the model stalls at pilot. In some cases, flawed deployments can even incur major losses. For example, Zillow Group had to shut down its AI-driven home-buying business in 2021, taking a $500+ million write-down when its pricing model badly misfired. These cautionary tales underscore the high stakes of getting AI into production properly. In short, closing the last mile is not just an IT issue, but a fiscal imperative.
Six (Plus One) Common Last-Mile Failure Modes
To better diagnose the last mile, we can categorize several frequent failure modes that derail AI deployments:
Each of these failure modes has different symptoms, but all result in the same outcome: the model fails to deliver value in production. By recognizing these patterns, organizations can anticipate pitfalls during the transition from lab to live deployment.
Root Causes
What underlies these failure modes? Five core root causes surface repeatedly:
· Lab-to-factory disconnect. Data science teams often optimize for offline accuracy (Kaggle-style leaderboard metrics), while IT and ops teams prioritize very different things: uptime, throughput, security, cost efficiency. This misalignment means a model that’s “great” in the lab may be entirely impractical in the real world.
· Siloed incentives. Business units own the process or business outcome, but not the model; data teams own the model, but not the day-to-day process. No group feels full accountability for making the whole solution work end-to-end. These silos create gaps in ownership after deployment (the aforementioned “vacuum”).
· Underinvestment in MLOps. Many organizations lack the tooling and infrastructure to support AI in production. Continuous integration/continuous delivery (CI/CD) for ML, feature stores, automated retraining pipelines, model performance monitoring – these operational capabilities are often missing or immature. AI is deployed like a one-off experiment, not a resilient IT service.
· Human factors. End users may distrust a “black box” model’s outputs or simply find that the AI doesn’t fit into their established decision flows. Without thoughtful change management, training, and UX design, even a valid model can be rejected by the people intended to use it. A lack of interpretability or clear benefit creates a barrier to adoption.
· Regulatory uncertainty. Rapidly evolving rules around AI create hesitation. For example, the EU’s new AI Act (Article 10) will require rigorous data quality, transparency, and risk management for high-risk AI systems. If an organization isn’t prepared to provide things like data lineage, explainability artifacts, and bias audits, compliance teams may preemptively block a deployment. In heavily regulated sectors, the fear of future regulatory scrutiny can itself become a last-mile obstacle. (Notably, U.S. and UK regulators have similarly emphasized ongoing model monitoring, human oversight, and accountability for AI in use.)
These root causes are often interrelated – and none can be solved by technology alone. They call for a holistic approach spanning design, process, and governance. In the next section, we outline such an approach: a four-part framework to engineer deployable, reliable, and trusted AI systems from the start.
A Four-Part Framework for Closing the Last Mile
No single tool or tactic will close the last mile; rather, success comes from weaving deployment considerations into every stage of the AI lifecycle. We propose a four-part framework to operationalize AI effectively:
1. Deployability by Design. Shift deployment to the left. Treat downstream production requirements as first-class design criteria, not afterthoughts. In practice, this means data science teams should build models with an eye on how they will run at scale, by:
· Containerizing early: Package the model environment (e.g. in a Docker/OCI image) during development so that production hand-off is seamless. If a notebook model can’t easily be containerized, that’s a red flag.
· Targeting portable formats: Use interoperable model formats (such as ONNX or TorchScript) so models can be deployed on a variety of platforms and infrastructures with minimal re-work.
· Budgeting inference costs: Incorporate latency and memory constraints into model selection and even into the loss function if possible – e.g. penalize overly complex ensembles that can’t meet real-time response needs.
A quick win is to require every lab model to ship with a one-click staging endpoint for inference. If the data science team cannot demonstrate the model running in a production-like environment (even on test data) at the end of development, then it’s not truly “ready.” By baking deployability into model development, organizations avoid the classic scenario of a brilliant model that can’t be operationalized due to engineering rework.
2. Model + Workflow Co-Design. An AI model only creates value when its output is actually used – by people or by downstream systems. It sounds obvious, but it’s often overlooked in AI projects. Co-designing the model and the business workflow means working with end-users from the start to ensure the AI fits seamlessly into decision-making processes:
· Map the decision points in the business workflow and insert the model’s predictions or recommendations at points where a decision can be improved – and in a format that the decision-maker can easily consume. For instance, if an AI generates risk scores for loans, integrate those scores into the loan officer’s existing dashboard or approval form at the moment they need to decide, rather than on a separate report they might ignore.
· Provide explainability aids alongside the model output. This could include rank-ordered feature contributions, scenario analysis tools, or reason codes – whatever helps a user trust and understand the recommendation. If users know why a model is suggesting something, they’re more likely to act on it.
· Align to human cognitive load: Determine the right sensitivity or threshold settings so that the AI doesn’t overwhelm users. For example, if a fraud detection model flags too many transactions, operators will experience alert fatigue. Co-design might involve raising the alert threshold or grouping alerts so that human analysts only see the most relevant, actionable cases (as we’ll see in the fraud case study below).
By developing the model with the workflow in mind (and vice versa), you ensure the AI augments and fits the human process instead of disrupting or complicating it. This greatly increases user adoption and impact.
3. MLOps and Post-Deployment Discipline. Treat deployed models as living systems that require care and monitoring, just like any mission-critical software service. Embracing modern MLOps practices is key to sustaining AI value:
· CI/CD for ML: Implement continuous integration and delivery pipelines that include automated testing of data and models. When a new model version is trained, it should pass integration tests, then be deployed – perhaps first as a canary or A/B test – with the ability to roll back if it underperforms. (This approach, common in software, needs adaptation for ML – testing not just code but also data and model quality.)
· Observability: Maintain real-time dashboards tracking the model’s performance in production – not only technical metrics like latency and error rates, but also data drift, prediction drift, and downstream business KPIs. Set up alerts for anomalies (e.g. the input data distribution shifting beyond the range seen in training, or a sudden drop in prediction confidence or accuracy). Early detection of issues allows teams to intervene before an unnoticed model failure causes damage.
· Automated retraining pipelines: Where appropriate, establish triggers for retraining or refreshing the model when conditions change. For example, if data drift exceeds a defined threshold or prediction error on recent validated cases crosses a limit, an automated job could kick off retraining using the latest data, followed by validation and deployment of a new model version. This keeps the model from going stale.
Surveys show that organizations with mature MLOps capabilities are far more likely to realize value from AI. In fact, a recent analysis found that companies proficient in scaling and operationalizing AI achieved roughly 3× higher ROI than those stuck in ad-hoc pilots. Yet most enterprises today see only single-digit returns on their AI investments, indicating substantial room for improvement. In short, disciplined operational practices distinguish AI initiatives that scale and succeed from those that stagnate.
4. Ownership & Trust Layer. Even the best technology won’t deliver value if there is no ownership and users don’t trust the system. The final layer of the framework emphasizes clear responsibility and user confidence:
· Appoint model owners and stewards. Define who in the organization is accountable for the success of each AI model in production (e.g. a “model product manager”). This includes monitoring performance, coordinating updates, and serving as point of contact for issues. Avoid the common “ownership vacuum” where everyone assumes someone else is taking care of the model.
· Build a feedback loop with users. Create channels for front-line users to report problems, ask questions, and suggest improvements to the AI tool. For instance, establish an AI helpdesk or Slack channel staffed by the data science or MLOps team. Demonstrating responsiveness to user feedback helps maintain trust and adoption.
· Incorporate explainability and guardrails. Provide documentation and interfaces that help users (and auditors) understand how the model works and when it might not. Simple steps like model fact sheets, bias audit results, and example-driven explanations can go a long way. Similarly, put guardrails in place – whether human review checkpoints, logical constraints, or adversarial input filters – to prevent the AI from doing damage if it behaves unexpectedly. This is especially crucial for generative AI systems that can produce incorrect or inappropriate outputs if misused.
· Monitor ethics and fairness continuously. Treat ethical AI metrics (bias, fairness, transparency) as ongoing operational metrics, not one-time checks. Incorporate bias detection into monitoring dashboards. Convene an AI oversight committee or similar governance body to review any high-stakes models periodically. Users and external stakeholders will trust AI more if they know active measures exist to keep it fair, safe, and compliant over time.
By implementing an Ownership & Trust layer, organizations ensure that AI systems have human accountability and earn user trust. This layer ties together the technical and organizational aspects of last-mile success, making AI adoption sustainable.
Case Studies
To illustrate how these principles come together in practice, here are three anonymized case studies, each highlighting a last-mile challenge and the solution that closed the gap:
Case 1: Retail Personalization Engine
· Problem: A large retailer developed a new AI-driven product recommender system. In A/B lab tests, the model showed impressive lift – it increased online conversion by +7 percentage points. However, when rolled out to stores, sales didn’t budge; the model’s recommendations weren’t driving any noticeable revenue uptick.
· Diagnostic: The issue wasn’t the model’s accuracy – it was operational friction. The marketing team received the recommender outputs via a dashboard, then had to manually export CSV files and import them into their campaign management tools to actually run personalized promotions. This batch, manual process was too time-consuming and didn’t fit their daily workflow. As a result, the local marketing managers simply didn’t bother – the model’s output sat on the shelf, a classic last-mile failure of workflow misfit.
· Fix: In the co-design phase of a revamp, the solution was to embed the model outputs directly into the marketers’ existing campaign tool. The recommender’s API was integrated with the campaign management platform so that each night the model’s recommended product segments would automatically populate and update within their normal campaign interface. Marketers could now simply click to deploy a tailored campaign, instead of wrestling with CSVs. With this seamless integration, adoption jumped to nearly 95% and the revenue lift from personalization materialized within two quarters. In essence, the model’s insight was finally delivered to the right place at the right time – unlocking the business value that had been there all along.
Case 2: Insurance Underwriting Model
· Problem: A property & casualty insurer built a sophisticated risk assessment model for underwriting policies. Technically, the model worked well and could have streamlined quote approvals. However, the underwriters refused to use it, calling it a “black box” and citing concerns that they didn’t understand its decisions. Deployment was effectively blocked by an internal trust and compliance issue.
· Diagnostic: This was a failure of user trust and explainability. The underwriters were on the hook for decisions, yet an opaque model was telling them how to price risk. With regulators and company policy emphasizing accountability, they were uncomfortable relying on an algorithm with no insight into its reasoning. The model had been developed in isolation, with little consideration for how to explain its outputs or involve underwriters in its design.
· Fix: The insurer implemented a two-part solution. First, they developed a “scenario explorer” tool for the model – essentially a simple interface where underwriters could adjust key input factors (coverage amount, asset details, etc.) and see how the model’s predicted risk or recommended price changed in real time. This gave underwriters a tangible feel for what the model was “thinking” (i.e. which factors were driving outcomes), building intuition and trust. Second, the company instituted a policy that any quote over a certain high threshold (e.g. $1 million) would automatically trigger a human review, no matter what the model said. This governance check reassured everyone that the AI wouldn’t be solely responsible for huge decisions. With these changes, underwriter trust climbed significantly and model-driven quotes rose from ~18% of total quotes to about 62% within six months. The model went from shelfware to a standard part of the underwriting workflow because users finally felt comfortable that it was a tool under their control, not an unaccountable black box.
Case 3: Banking Fraud Detection
· Problem: A retail bank deployed a machine learning model to flag likely fraudulent transactions. The model worked – perhaps too well. Upon initial deployment it generated far more alerts than the fraud operations team could handle, many of which turned out to be false alarms. Overwhelmed by volume and noise, the human investigators experienced alert fatigue. They started to ignore many of the model’s alerts or turned off notifications, meaning real fraud incidents might slip through. The last-mile issue here was a mix of threshold calibration and human-in-the-loop design.
· Diagnostic: The model had been tuned for high sensitivity (catch every possible fraud), but the organization hadn’t adjusted processes or thresholds to manage the workload. There was no active learning or feedback loop in place; it was a one-way stream of alerts to humans who then fell behind. In effect, the deployment lacked the MLOps discipline and workflow alignment to refine performance in production.
· Fix: The bank took a step back and applied two key fixes. First, they calibrated the model’s confidence threshold for flagging fraud, to reduce the initial alert volume to a manageable level. Rather than alerting on every transaction with (say) >50% predicted fraud risk, they raised the threshold so that fewer, higher-confidence cases were surfaced automatically, while lower-confidence cases were batched or queued for further analysis. Second, they implemented an active learning loop: alerts that investigators reviewed and found to be false positives were fed back as labeled examples, and the model was retrained periodically (e.g. weekly) to improve precision over time. These changes had a dramatic impact – the model’s false-positive rate fell by ~40%, and the analysts’ workload dropped by one-third thanks to more precise alerts. By adjusting the last-mile deployment (thresholds, feedback process, retraining cadence), the AI went from overwhelming to truly enabling the fraud-fighting team.
Regulatory and Governance Lens
Policymakers and regulators are increasingly zeroing in on this last-mile gap, linking technical deployment with governance and risk management requirements:
· EU AI Act (2024). The European Union’s AI Act – slated to come into force in the next few years – directly targets many last-mile issues. For example, Article 10 of the Act mandates that high-risk AI systems be trained on high-quality, representative, and error-free data, and that organizations maintain detailed data and model documentation for scrutiny. In essence it requires that deployability planning include documentation, data lineage, and explainability artifacts ready for auditors. Companies will need robust data provenance capture, model “cards,” and monitoring logs as part of any compliant production AI system.
· Industry-specific regulations. Sector regulators are also issuing AI guidance. In financial services, for instance, the UK’s Financial Conduct Authority (FCA) and the U.S. Consumer Financial Protection Bureau (CFPB) have made it clear they expect firms to monitor and manage their models continuously for fairness, transparency, and performance. The FCA has stressed that firms must retain human oversight of AI-driven decisions and be able to explain and justify those decisions to regulators. In the US, the proposed Algorithmic Accountability Act would require companies to conduct impact assessments on AI systems to check for bias or disparate impact before deployment. Meanwhile, the U.S. FDA now requires post-market surveillance of AI in medical devices to ensure safety and efficacy over time. All these developments point to the need for strong last-mile controls – from testing and bias mitigation to ongoing monitoring and human-in-the-loop mechanisms – baked into AI deployments from day one.
· AI accountability frameworks. Beyond hard law, new frameworks and standards are emerging to guide AI governance. For example, NIST’s AI Risk Management Framework (AI RMF) in the U.S. and the upcoming ISO 42001 AI Management System standard both emphasize operational monitoring, incident response, and human oversight for AI systems in production. These guidelines align directly with the Ownership & Trust layer described above – insisting on clear accountability, transparency, and mechanisms to intervene if an AI system behaves unexpectedly. Notably, ensuring security against adversarial manipulation is increasingly seen as part of reliability; organizations are expected to consider and mitigate risks like data poisoning or model exploitation as part of their AI governance. Companies that adopt these best practices not only reduce their regulatory risk, but also improve the resilience and trustworthiness of their AI in the eyes of users and regulators.
Conclusion
AI’s last-mile problem is the chief bottleneck between promising pilots and scaled impact. It is a socio-technical challenge: models may be technically sound, but organizational readiness, process integration, and trust are often lacking. The encouraging news is that these failure modes are well-understood, and so are the remedies. By designing for deployability from the outset, co-creating workflows with end-users, instilling rigorous MLOps discipline, and building an ownership and trust culture around AI, organizations can systematically break out of pilot purgatory.
The difference between sporadic AI “experiments” and a truly AI-driven enterprise comes down to execution in that final mile. Firms that close the last-mile gap will move faster from lab concept to business value, converting AI investments into measurable ROI and competitive advantage. In the coming era, the winners will be those who can reliably put AI into action, not just into slide decks. The last mile is where that battle will be won or lost.
References
· Appen (2024). 2024 State of AI Report (industry survey findings). Appen, Oct 2024. Summary available in VentureBeat: M. Núñez (2024), “Generative AI grows 17% in 2024, but data quality plummets: Key findings from Appen’s State of AI report.”
· BusinessWire (2024). “Why 85 percent of AI projects fail and how to save yours.” Press release (Nov 15, 2024), reported via Forbes Technology Council.
· European Parliament and Council (2024). Regulation (EU) 2024/1689 (EU AI Act), Article 10 (data and data governance requirements for high-risk AI). Official Journal of the EU, 13 March 2024.
· Lenovo & IDC (2025). Lenovo Global AI Study 2025. IDC research report (finding ~88% of AI POCs don’t reach production). Findings cited in: E. Schuman (2025), “88% of AI pilots fail to reach production — but that’s not all on IT,” CIO.com (Mar 25, 2025).
· MIT Sloan Management Review & BCG (2021). The Cultural Benefits of Artificial Intelligence in the Enterprise (5th Annual Global AI Survey). Cambridge, MA: MIT SMR/BCG.
· RAND Corporation (2023). The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed: Avoiding the Anti-Patterns of AI. RAND Research Report RRA2680-1 (Aug 2023).
· Virtasant (2025). “AI Operational Efficiency: Navigating GenAI’s True Cost.” Virtasant Blog (10 Mar 2025).
· Wall Street Journal (2025). “Companies Are Struggling to Drive a Return on AI – It Doesn’t Have to Be That Way.” Wall Street Journal, Apr 26, 2025 (S. Rosenbush).
· U.S. Congress (2023). Algorithmic Accountability Act of 2023. S.2892, 118th Congress (bill introduced Sept 21, 2023). Washington, DC: U.S. Senate.
View related posts

AI Total Cost of Ownership (TCO): The Hidden Cost of Inference
AI inference drives up to 90% of costs. LexData Labs cuts TCO by 68% with model right-sizing, automation, and edge deployments.
.jpg)
.jpg)
Start your next project with high-quality data
