The True Cost of Artificial Intelligence
“As datacenter production gets automated, the cost of intelligence should eventually converge to near the cost of electricity.” — Sam Altman, The Gentle Singularity
.jpg)
Executive Summary
Contrary to what Sam Altman has stated, the true cost of artificial intelligence remains far from “just electricity.” In a typical hyperscale AI operation, power for electricity and cooling accounts for only ~15–25% of total expenditure – i.e. under a quarter of the budget. The bulk of AI costs come from other layers: expensive hardware (GPUs costing ~$30,000 each), data center infrastructure, skilled human talent, and profit margins added by providers. For example, training GPT-4 likely required well over $100 million in compute, and cloud giants like AWS enjoy operating profit margins north of 35% – meaning customers pay a premium far above raw power utility costs. Even in an ideal scenario where all other costs were halved, electricity’s share would rise to only ~40% of total AI cost – nowhere near 100%. In short, the optimistic claim that “AI cost ≈ price of electricity” does not hold water once one accounts for silicon, facilities, R&D, networking, and corporate overhead (Cloudflare, 2021; Wired, 2023). AI’s cost structure is diverse, and energy is just one slice of a much larger pie.
Big Tech’s own playbook underscores this reality. Historically, tech giants entice users with subsidized “free” services, then monetize heavily once dependence grows. We see this with cloud computing (free ingress, costly egress) and now AI: early generous access to models is giving way to steep fees. Twitter’s API, once free, now charges ~$42,000/month for enterprise access (NYT, 2023). OpenAI initially let the world experiment with ChatGPT for free, but is now upselling organizations to paid plans and higher-priced API tiers. These companies must recoup massive investments in GPUs, data centers, and research – and satisfy investors expecting >25% margins. Bottom line: The cost of delivering AI at scale will not magically drop to the cost of electricity alone, because vendors will always layer in capital costs and profit. Instead, organizations need a holistic cost strategy. Techniques like model compression, optimized hardware usage, and edge computing can dramatically reduce AI costs today. In one case, distilling a large AI model slashed cloud inference spend by >250× (from ~$1.4M to $6K per year) with negligible accuracy loss. By attacking every cost layer – model size, runtime platform, data transfer, and retraining efficiency – companies can transform AI from a budget-buster into a high-ROI investment. The following analysis breaks down where AI costs come from and how a light-weight AI stack can rein them in.
Hyperscale AI Stack: Real Cost Breakdown
In practice, the total cost of AI is the sum of many parts. A rough breakdown for a hyperscale data center looks like this:
· Power & Cooling (~15–25%) – The electricity to run servers and the cooling overhead. Advanced cooling (lower PUE) helps, but each new model generation needs ever more FLOPs. Global data centers drew ~460 TWh in 2022 (about 2% of global electricity). In practice, only ~1/5 of total AI cost goes to kilowatt-hours. Even if every other cost were halved, power’s share would still only reach ~40%.
· GPU & Server CAPEX (~35–45%) – Top-tier AI hardware is expensive. An Nvidia H100 GPU can cost on the order of $30,000. A single AI server can exceed $400K for a multi-GPU setup. These capital costs – GPUs/TPUs, CPUs, high-bandwidth memory – are often the largest line item. Depreciated over 3–4 years, silicon remains king. Cutting-edge 5 nm and 3 nm chips with HBM aren’t cheap, and supply is constrained.
· Facilities & Infrastructure (~10–15%) – Building the data center shell, power and cooling systems, etc., costs real money. A rule of thumb: ~$10 million per MW of IT load. That includes everything from concrete, steel, and land to generators and UPS units. (One new 170,000 m² Singapore data center will use 150 MW when fully operational.) These costs don’t disappear with automation – someone finances the buildings and grid upgrades.
· Network & Storage (≈5–10% OPEX) – Moving and storing data also adds up. Petabytes flow across regions daily for replication, backup, and user requests. Importantly, public cloud egress fees are notorious: wholesale bandwidth costs fell ~93% over 10 years, but AWS’s data egress prices fell only ~25%. Each byte out of the cloud costs real dollars. Content delivery networks (CDNs), inter-region traffic, and distributed storage all contribute to this ongoing cost.
· R&D and Training (~10–20%) – Developing and refining AI models is expensive. Training a single GPT-class model can cost nine figures – e.g. GPT-4’s training likely ran on the order of $100–160 million in compute (Wired, 2023). Beyond cloud compute, organizations pay hefty salaries to AI researchers, data engineers, annotators, and DevOps. These human and experimentation costs are substantial ongoing expenses to keep improving models.
· Profit & Overhead (~5–15%) – Lastly, tech firms aren’t charities. Providers bake in corporate overhead and a profit margin on AI services. Major cloud operators today report healthy margins – for example, AWS’s cloud operating margin was ~37% in Q4 2024 (ValueSense, 2025) and Google Cloud’s was ~14% after finally turning profitable in 2024. Microsoft’s overall net profit margin hovers ~35–36%. Investors expect returns, so the price customers pay will always include some markup over raw cost. In other words, electricity may be the floor on cost, but it’s nowhere near the whole story once corporate overhead and profit are included.
Bottom line: Even best-in-class AI operators spend well under a quarter of their budget on electricity. No amount of futurism changes that reality. An aggressive scenario that somehow slashed all other costs in half would still leave power <40% of the total. That’s a far cry from “nearly 100%.” Any theory that electricity alone will dominate AI costs neglects the silicon, facilities, network, R&D, and profit layers that make up the stack.
Why Power Alone Can’t Dominate
Why can’t we reach a world where cost = just electricity? A few inescapable reasons:
· Silicon scarcity. Cutting-edge GPUs need exotic materials (e.g. HBM3E memory) and bleeding-edge fabrication (5 nm, 3 nm nodes). These specialty parts are supply-constrained and pricey. Until truly disruptive hardware (photonic, quantum, etc.) arrives and becomes affordable, you pay a premium for high-FLOP silicon. Even if electricity cost per FLOP keeps dropping, the silicon cost per FLOP must drop similarly – otherwise power can’t dominate total cost. (On paper, AMD’s new MI300X GPU promises ~1.31 PFLOPs vs. 0.99 PFLOPs for Nvidia’s H100, but real-world gains depend on software and don’t come cheap or easy.)
· CAPEX refresh cycles. Data centers are built in multi-decade waves. At ~$10M per MW of capacity, operators must amortize enormous capital outlays. Servers typically depreciate over ~3 years, facilities over ~10+ years. No matter how efficient automation gets, someone is financing that $10M/MW build and expecting payback. Those capital costs – and any debt servicing – remain in the equation. We can’t “innovate away” the fact that new capacity requires big upfront investment.
· Grid & cooling limits. Frontier AI clusters demand massive power and cooling. For example, Meta’s newest Singapore campus is designed for 150 MW of IT load – an unprecedented scale in that region. Securing hundreds of megawatts from the grid (plus water and chillers to cool it) is a major infrastructure project in itself. High-density liquid cooling systems can cost tens of millions more. Governments and utilities may require operators to invest in grid upgrades or on-site generation. These non-kWh infrastructure costs stack on top of the power bill.
· Human R&D loop. Cutting-edge AI isn’t a solved problem that runs itself – far from it. Companies like OpenAI, Anthropic, and Google are still pouring billions into discovering new model architectures, fine-tuning techniques, safety alignment, etc. Advanced automation can streamline infrastructure management, but it cannot replace the human creativity and research needed for breakthroughs. The human side of innovation (research talent, compliance teams, data sourcing) keeps R&D budgets high. In short, AI progress remains labor-intensive, and those skilled people don’t work for free.
· Regulatory & carbon drag. Governments are starting to tax or regulate data center inputs beyond just electricity. The EU’s new Energy Efficiency Directive (EU 2023/1791) will force data centers >500 kW to measure and report energy and water usage and efficiency metrics each year (EU, 2023). The upcoming EU AI Act (expected 2024) will impose compliance overhead (documentation, audits) and can fine violators up to €35 million or 7% of global revenue for high-risk AI abuses (EU, 2025). In the U.S., states like California are crafting rules to protect the grid – for example, SB 57 (Padilla, 2025) and AB 222 (Bauer-Kahan, 2025) propose special utility tariffs so that large data centers bear the full cost of grid upgrades (ensuring ordinary ratepayers aren’t stuck with the bill). California is also considering mandates for AI compute transparency (reporting energy used in model training). Meanwhile, Singapore’s Green Mark 2025 standards will require new data centers to hit aggressive efficiency targets (e.g. PUE ≤1.39 for top-tier certification, down from 1.5) and meet water-saving and waste-heat reuse criteria (BCA, 2024). These compliance costs – from sustainability reporting to potential carbon taxes – add overhead that has nothing to do with your kWh meter. The upshot: as AI scales, regulatory burdens will increase, not vanish, keeping non-power costs in play.
In short, only at the extreme “bare-metal” edge – say, a tiny microcontroller running a small vision model – does marginal cost approach pure watts. For full-scale, enterprise-grade LLMs and GPU farms, hoping for “AI = free electricity” is wishful thinking. Big Tech knows this, which leads to the next point.
Big Tech’s Profit Motive: A Land-Grab Playbook
This pattern is by design. In each previous tech wave, giants offered “free” or subsidized on-ramps, built huge user bases, then tightened pricing once customers were dependent. Consider:
· Social Networks (circa 2008–2014): Platforms like Facebook and Twitter enticed billions of users with free unlimited features – unlimited photo uploads, ad-free feeds, open APIs for developers, etc. Once the networks became entrenched, monetization ramped up. Facebook and Instagram crammed feeds full of ads and throttled organic reach unless you pay. Twitter (now X) famously shut off its free API in 2023 and started charging developers exorbitant fees (the basic Enterprise API package is ~$42,000 per month – essentially charging for what used to be free community data). “If you’re not paying, you’re the product” became the rule as social media companies squeezed revenue from their captive audiences.
· Cloud Computing (2010s): Major cloud providers offered generous free tiers and credits early on to attract startups and enterprises – and free ingress of data into the cloud. But once workloads migrated, they knew egress fees and value-added services could lock customers in. Today, AWS’s data transfer fees remain steep (and static) despite plummeting bandwidth costs. Many early cloud “freebies” (like unlimited API calls or monitoring metrics) have since become paid tiers. Cloud giants also bundle proprietary PaaS products that are easy to adopt but hard to replace, raising switching costs. The result: customers face steadily increasing cloud bills over time, especially if they need to pull data out or use premium managed services.
· Generative AI (2023–today): We’re seeing the same land-grab now in AI. Early adopters received free or heavily discounted access to foundation models or millions of “promo” tokens on new AI APIs. But that honeymoon is ending. OpenAI, for example, initially let users experiment with GPT-4 (via ChatGPT) for free or $20/month, but is now upselling organizations to much pricier enterprise plans (with higher rate limits and data privacy) and charging for premium API tiers. OpenAI’s API prices even increased for some uses in 2024 when they introduced more expensive 32k-context models, and rumors suggest a minimum spend requirement for enterprise API access. Competitors like Anthropic offered free trials of Claude models, then introduced paid subscriptions (Claude Pro) and higher prices for the 100k-token context version. Even open-source-centric firms such as Hugging Face – which grew famous for free model hosting – now monetize via enterprise offerings and hosted inference APIs, driving their ARR from near-zero to an estimated $70 million in 2023 (Sacra, 2024). The playbook: get users hooked on “free” AI, then charge for higher usage or make them pay for premium features/support once it’s mission-critical.
Why do they do this? Because the investors behind these companies demand returns. Even if technically an AI query might cost only a fraction of a cent in electricity, the big providers have profit margins north of 25% to maintain. They will price services such that their margin is captured. In cloud computing – a trillion-dollar market – AWS is one of the only players with sustained high profitability. The others are striving to get there. So long as customers are willing to pay for reliability, scale, and performance, vendors will charge a premium over raw cost. Electricity is just the floor; Big Tech is aiming for the ceiling. The era of heavily subsidized AI usage (e.g. unlimited free ChatGPT) is likely to taper off as monetization pressures grow.
The LexData Labs Answer: Light-Weight Compute
If we’re not going to wait for electricity to magically become the only cost, what can practical AI teams do today to slash expenses? LexData Labs advocates a right-sized approach – attacking every cost bucket through four key levers:
1. Model Distillation & Quantization: Compress large models into leaner versions. Modern knowledge distillation can shrink a model’s size by 10× or more with minimal accuracy loss, meaning you need far fewer GPUs (CAPEX ↓) and use far less energy per inference (Power/Cooling ↓). For example, replacing an 800 MB transformer with a distilled 90 MB model can cut inference costs by orders of magnitude while staying within a point or two of the original accuracy.
2. CPU-First Serving: Leverage optimized CPU inference for suitable workloads. A modern CPU instance (e.g. a $0.04/hr cloud VM) can handle many small-to-medium models in milliseconds – orders of magnitude cheaper than a $0.50+ per hour GPU instance. Using CPUs at scale eliminates the “GPU tax” premiums and sharply reduces on-demand OPEX for inference. In practice, routing the majority of queries to cheap CPU cores can wipe out >90% of the serving bill compared to naïve all-GPU deployment, with negligible latency impact for many apps.
3. Edge & On-Device Execution: When viable, consider moving model execution out of the cloud entirely. Running AI models in-browser, on smartphones, or on IoT devices means zero cloud compute cost for those inferences and zero network egress fees. It can also improve privacy and latency. Even offloading a portion of traffic to the edge – say, doing initial screening of images or text locally – can materially shrink your cloud compute and data transfer bills.
4. Active Learning & Efficient Training: Use smart data strategies to minimize retraining work. Rather than re-training large models from scratch on every new dataset, techniques like active learning identify the most informative new data and focus human labeling effort there. Recycle and re-use model knowledge through fine-tuning and transfer learning, instead of brute-force training from scratch. This “refine instead of redo” approach cuts down on wasted GPU training cycles and massive synthetic data generation – directly lowering R&D and storage costs.
These levers compound. Case in point: in one client engagement, applying aggressive distillation plus other optimizations shrank an 800 MB NLP model down to 90 MB, slashing annual cloud inference spend from roughly $1.4 million to $6,000 – a >250× reduction – while the model’s accuracy (F1 score) stayed virtually unchanged. By contrast, simply hoping for hardware or electricity to get 10× cheaper would take years (if it happens at all). The lesson is that smart engineering can unlock immediate savings that dwarf what waiting for Moore’s Law or utility rebates might yield.
Mini-Case: LLM Distillation Yields 250× Cost Savings. A financial services firm was struggling with a large language model deployment that was costing over $100k per month in GPU inference charges for customer queries. Model distillation compressed their 6-billion-parameter model into a 300-million-parameter version, and quantized it to INT8. The distilled model’s accuracy on key tasks dropped by <2 percentage points, but it could be served on commodity CPUs. The result: inference costs fell by 99.6% (from seven figures per year down to low five figures). This is the power of a model “diet” – cutting silicon and power costs together by simply doing more with less.
Putting It Together – A Realistic AI Cost Stack
In reality, there is no silver bullet. Companies must attack every layer of cost. The figure below illustrates an example breakdown of a baseline AI stack versus a light-weight optimized stack after applying the techniques outlined above. In the baseline, GPU/ASIC capital expenditures alone make up the largest share of total cost (~38%), followed by significant allocations for R&D, infrastructure, and vendor profit margins. Electricity and cooling, while often discussed as the dominant input, account for only ~20%. In the optimized light-weight scenario, overall costs shrink and the composition shifts — electricity rises to ~40% of the total, not because power costs increased, but because other categories like silicon, networking, and vendor markup were aggressively reduced. This underscores a key point: power is never the only cost that matters. Optimizing AI economics requires managing every layer of the stack.
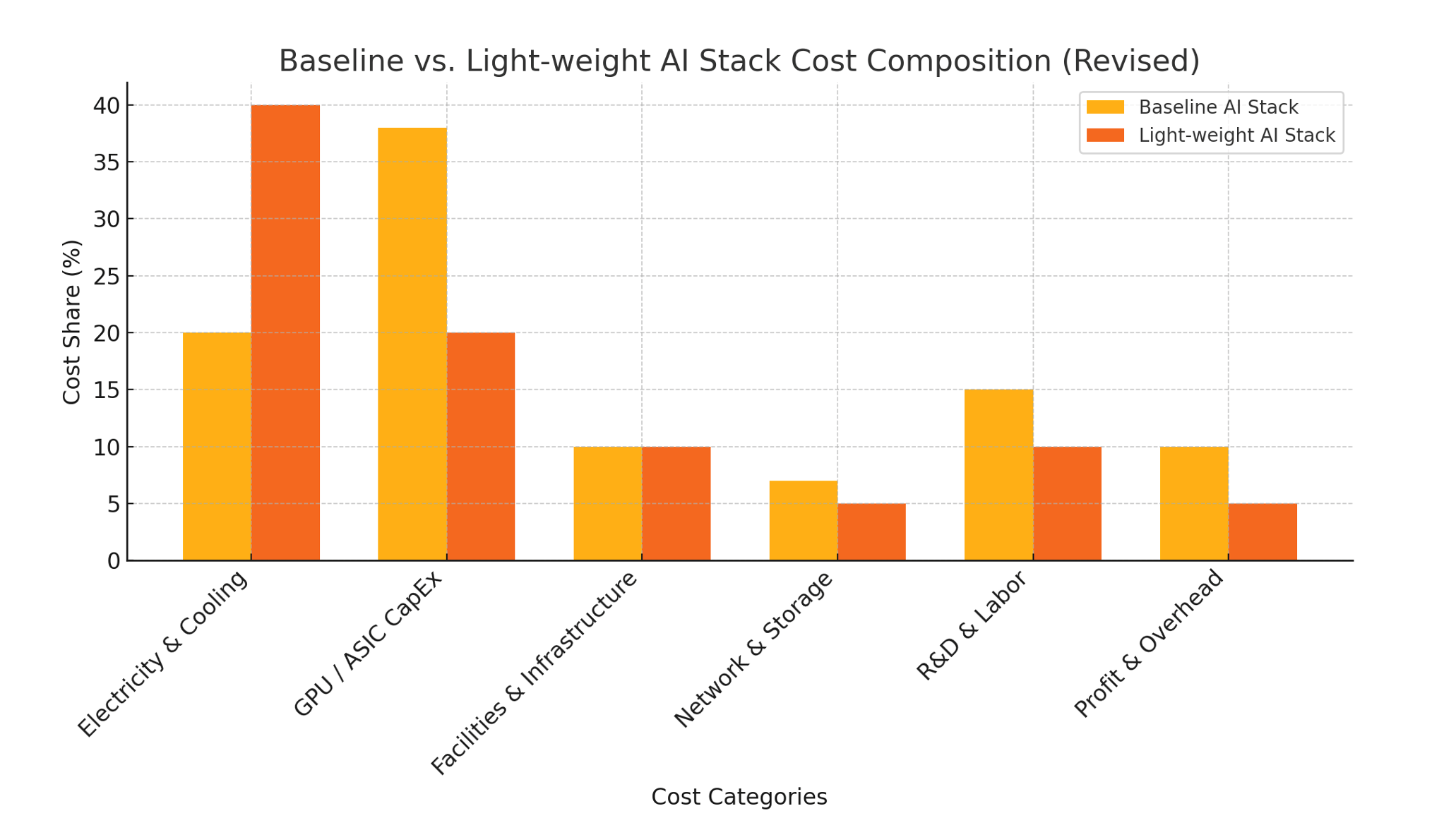
Baseline vs. Light-weight AI Stack Cost Composition. In the baseline scenario (left), electricity & cooling form ~20% of total AI cost, with GPU/ASIC CapEx (~38%) and other costs dominating. In the optimized light-weight stack (right), total costs are dramatically lower and electricity’s share grows to ~40% – not because power became more expensive, but because other categories (hardware, infrastructure, network, profit) were minimized. Even after aggressive optimizations, significant spend remains in non-power areas, underscoring that AI cost is a multi-faceted stack, not just an energy bill.
In other words, you might push electricity’s share from ~20% up to ~40% with extreme engineering efficiency – but you’ll never get to a world where it’s 90%+. There will always be significant spend on hardware, people, facilities, and supplier margins. The good news is that by attacking those dimensions proactively, you can achieve dramatic savings. Our recommended playbook in summary:
· Model Diet – Shrink models (distill, quantize) to cut both silicon and power costs.
· Smart Scaling – Match your deployed compute to actual demand (avoid 24×7 idle over-provisioning).
· Edge Shift – Move appropriate workloads off the cloud or closer to users (erase network fees and cloud markup).
· Continuous Care – Keep models lean, updated, and monitored so you don’t waste money on redundant retraining or late fixes (which can incur compliance costs too).
LexData Labs’ light-weight AI stack is built around total TCO – not just one component – because that’s what drives bottom-line impact.
Mini-Case: Edge Vision Model Eliminates Cloud Costs. Consider a retail chain using in-store cameras for inventory counting and security. Originally, every camera stream was sent to a cloud vision API for analysis – consuming terabytes of bandwidth monthly. Besides latency, this racked up hefty egress charges (several thousand dollars per store per year, at typical cloud rates). Instead, compact vision models were deployed on cheap edge devices (Jetson kits) in each store. Now, video is analyzed locally in real time; only high-level results (counts, alerts) are sent to the cloud. The outcome: >95% reduction in cloud bandwidth usage, saving an estimated $10,000+ annually in data fees for a mid-sized deployment, and improving response time. Multiply that by dozens of stores, and the cloud savings are in the six figures – not to mention no dependency on an expensive cloud AI service. This showcases how edge computing can cut both network and cloud compute costs to near zero for suitable AI workloads.
Conclusion
For business leaders, the takeaway is clear: don’t buy into simplifications that the cost of AI will soon trend toward the cost of electricity. In practice, AI entails a diverse cost structure, and sustainable cost management means attacking waste in every category – right-sizing models and hardware, negotiating smarter cloud terms (or avoiding cloud lock-in), and anticipating regulatory impacts. The era of “free lunch” AI – where big platforms subsidize usage to gain market share – is winding down. Going forward, organizations must be intentional about AI deployment choices to avoid surprise bills and preserve margins. Those that lean into efficient, light-weight AI today can capture most of the value that ubiquitous “cheap intelligence” promises – without waiting years for theoretical tech breakthroughs or suffering sticker shock from cloud invoices.
Ultimately, AI cost optimization is a strategic issue. By taking a full-stack view – from chips and power to productivity and risk – you can turn AI from a budget-buster into a high-ROI investment. We’re confident that, in concrete dollars and cents, the “true cost of AI” can be far lower than what many teams are paying today – and we’re here to help make that happen.
References
· Bauer-Kahan, R. (2025). California Assembly Bill 222 (2025–2026 Session) – Data centers and grid upgrades (proposed legislation). Sacramento, CA: California State Assembly.
· BCA (2024). Green Mark 2025 – Data Centre Standard. Building and Construction Authority (Singapore), updated 2024.
· Cloudflare (2021). AWS’s Egregious Egress. Cloudflare Blog, 23 July 2021.
· EU (2023). Directive (EU) 2023/1791 on Energy Efficiency. Official Journal of the European Union, 2023.
· EU (2025). EU Artificial Intelligence Act (High-Risk AI Regulation). European Commission proposal
· New York Times (2023). Twitter’s New API Pricing Sparks Backlash from Developers.
· Padilla, S. (2025). California Senate Bill 57 (2025–2026 Session) – Electrical tariffs for data centers (proposed legislation). Sacramento, CA: California State Senate.
· Sacra (2024). Hugging Face: the $70M/year anti-OpenAI growing 367% YoY.
· Shilov, A. (2024). Nvidia’s H100 AI GPUs Cost up to Four Times More Than AMD’s MI300X.
· ValueSense (2025). AWS vs Google Cloud: Which Stock Offers Better Value? V
· Wired (2023). OpenAI’s CEO Says the Age of Giant AI Models Is Already Over.
View related posts

AI Total Cost of Ownership (TCO): The Hidden Cost of Inference
AI inference drives up to 90% of costs. LexData Labs cuts TCO by 68% with model right-sizing, automation, and edge deployments.
.png)
.jpg)
Start your next project with high-quality data
